ESID was one of the most formative long-term projects in my early medical informatics career. Through the ESID Registry I had the opportunity to work at the intersection of clinical data quality, registry design, modern database engineering, and distributed reporting systems. It was also the first project where I was able to present work at international conferences early on, and where I could demonstrate empirically that plausibility checks directly lead to higher data quality — an insight that later influenced several follow-up systems.
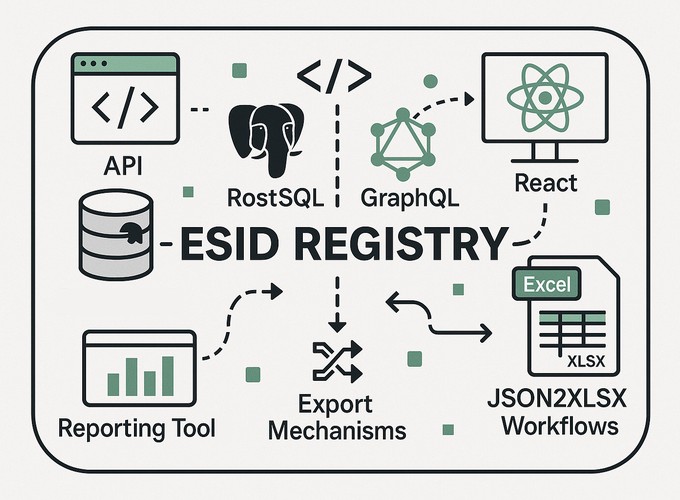
During the early phase of the redesigned ESID registry, the system itself had already been implemented by the core development group. My role focused on publishing the new registry through an Application Note and presenting its concepts and early insights at ESID meetings. In addition, I developed several of the technical components that became central to the operational ecosystem around the registry, most notably the reporting tool, various export mechanisms (including automated email-based exports), and supporting infrastructure for data access and data delivery. Through these contributions I helped make the registry more accessible, more analyzable, and more useful for both clinicians and researchers.
A major part of my ESID work centered on the reporting and export infrastructure surrounding the registry. While the registry itself was already in place, its operational ecosystem required modernisation. I developed the reporting tool, which unified several existing data flows, including the integration of UKPID registry exports via custom software. As part of this effort, the underlying database was periodically migrated from MySQL to PostgreSQL in an automated pipeline, enabling more robust data handling and laying the foundation for secure, structured access mechanisms such as Row-Level Security. This environment later supported API-based data retrieval, export interfaces, and interactive reporting functions for both internal and external stakeholders. The pipeline was later stabilized and re-implemented as Snakemake workflow.
With PostgreSQL in place, we implemented a modern API using the SubZero stack, enabling safe and structured data access. Row-Level Security (RLS) policies were deployed across all tables to guarantee user-specific and registry-specific permissions. In the internal area of the platform, permitted users could generate exports, including specialized outputs such as the APDS study dataset. The system was built around RabbitMQ and Socket-based notifications. The frontend was developed in React and consumed a GraphQL interface built on top of the API layer. The public-facing side provided global registry statistics, while the internal dashboard showed the subset of data relevant to the logged-in user’s registry assignment.
Later, there were plans to migrate the entire reporting solution to Apache Superset. Initial groundwork was completed: a connection to the user directory was implemented, and the database was preconfigured with RLS so that dashboards would automatically respect each user’s data access permissions. However, due to limited resources and the end of the contract period, the full migration was ultimately not carried out.
The APDS study was an important use case within the ESID ecosystem. Its dataset required a human-readable export format despite being based on nested data structures. To make these structures visually intuitive, we created a color-coded Excel representation that allowed clinicians to interpret hierarchical data at a glance within a so called sparse spreadsheet. The tool was named Json2Xlsx and was later published in Software Impacts. This export mechanism supported numerous APDS publications and was also used for data exports to industry partners.
A further component connected to the ESID ecosystem involved the integration of ESID within the German PID-NET infrastructure using the OSSE registry framework. This was documented in a dedicated publication describing how the OSSE bridgehead enables interoperability between the customized ESID registry and the wider network of rare disease registries. While my own work focused primarily on reporting, export mechanisms, API access, and data delivery around ESID, this paper provides the architectural context in which our technical ecosystem operated: it shows how the ESID registry can participate in decentralized, federated queries without relinquishing data sovereignty, and how OSSE acts as an interoperability layer for national and international collaborative research. The approach demonstrated how a highly customized registry like ESID can connect to the OSSE platform via a free and maintainable toolchain, illustrating the broader interoperability landscape in which my ESID-related technical contributions were embedded.
Overall, ESID represents a central pillar of my early work in registry design, data quality, API-driven architectures, and secure access control via PostgreSQL and RLS. It is one of the projects where methodological development, practical clinical utility, and research contributions came together in a meaningful way, and one that influenced how I approached subsequent registry and data pipeline projects.
Links & Resources
New ESID Registry – Application Note:
https://academic.oup.com/bioinformatics/article/35/24/5367/5526873ESID Reporting Tool:
https://cci-reporting.uniklinik-freiburg.de/#/ESID Registry Overview (2020, Frontiers in Immunology):
https://pmc.ncbi.nlm.nih.gov/articles/PMC7578818/ESID Registry Working Party:
https://esid.org/working-parties/registry-working-party/